

[ comments ]
Simon is the creator of Datasette and co-creator of Django web framework. Formerly he was a JSK journalism fellow at Stanford, and prior to that an Engineering Director at Eventbrite.


I am very happy to introduce our first Arc Note with Simon Willison who is going to be talking about Datasette, SQLite and the challenges of building a server-side web application that also works in both Electron and WebAssembly. Its a great read — I hope you enjoy and hopefully learn a little something.
Who are you?
I’ve been building web applications since the first dot-com boom back in 1999. I started out in the very early days of online gaming, building community websites and running a news site (we didn’t call them blogs yet) and online league for the Half-Life mod Team Fortress Classic.
During my computer science degree I took a “year in industry” paid internship program in Lawrence, Kansas where I worked with Adrian Holovaty to build a CMS for a local newspaper using Python - this later became the open source Django web framework.
I later worked for the Guardian newspaper in London building tools for data journalism, including a crowdsourcing application for analyzing UK Members of Parliament expense claims.
After the Guardian I went on an extended honeymoon with my partner Natalie Downe during which we accidentally started a startup together. This was Lanyrd, a website to help people find conferences to attend and build a profile of events they had attended and spoken at. We took Lanyrd through Y Combinator, raised a seed round and three years later sold the company to Eventbrite and moved from London to San Francisco with our team.
My first role at Eventbrite was as the engineering director for the architecture team, helping to solve scaling problems, shepherding Eventbrite’s adoption of microservices and migrating team development environments to Docker. I later took on a R&D role exploring new ways to help users discover events relevant to them.
My true passion remained data journalism. I originally started Datasette as a side-project, exploring data publishing challenges I had wanted to solve years earlier at the Guardian. I left Eventbrite to participate in the JSK journalism fellowship program at Stanford, which afforded me a full year to dedicate to my open source data journalism projects. I’ve been working full-time on Datasette and related projects ever since.
What are you building?
My breakthrough was the realization that read-only data packaged as a SQLite database could be deployed to inexpensive serverless hosting
Simon Willison
Datasette is a tool for exploring and publishing data. The original goal of the project was to make it easy and inexpensive to publish structured datasets online. This was inspired by my time at the Guardian, where we launched a Data Blog to publish the raw data behind our stories. We used Google Sheets to share data there, but I always felt there should be a more powerful and flexible way to share data.
I want to encourage more news organizations - and other groups that control and gather useful data - to publish their databases. As such, I wanted a system that could be run as cheaply as possible while providing maximum power and flexibility to people trying to make use of that data.
My breakthrough was the realization that read-only data packaged as a SQLite database could be deployed to inexpensive serverless hosting, where it could scale from zero (costing nothing) up to handling an unlimited amount of inbound traffic.
Since releasing the first version nearly five years ago, my ambitions have expanded. I added support for writable databases via plugin hooks a few releases ago, and I’m now starting to build out features that let people build databases directly in Datasette in addition to exploring and publishing databases that already exist.
High Level Architecture Design
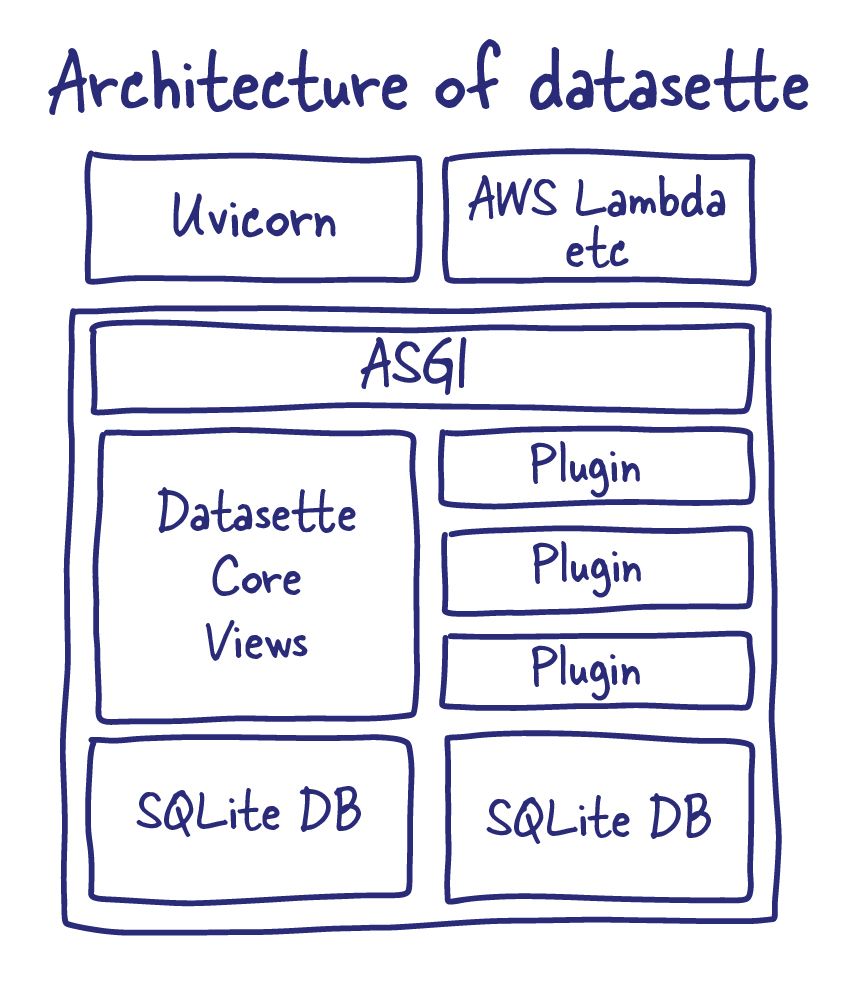
There are currently three distributions of Datasette: Datasette, Datasette Desktop and Datasette Lite.
- Datasette is the core Python web application, distributed as a Python package with a CLI interface for running a server. This can be run locally but is also designed to be deployed to hosting providers such as Google Cloud Run, Heroku, Fly, Vercel and more.
- Datasette Desktop packages up Desktop inside an Electron desktop application for macOS, primarily to help users who aren’t familiar with CLI applications.
- Datasette Lite uses Pyodide to run the full Datasette Python application entirely in the user’s browser. This helps people use Datasette when they do not have the capacity to host a Python server somewhere.
Datasette is a web application written in Python. The core application ships as a Python package which bundles its own web server, so you can start Datasette running on localhost like this:
pip install datasette # Or “brew install datasette”
datasette myfile.db
This will start a server running on port 8001 serving the default Datasette application.
ASGI
Datasette is built using ASGI. ASGI is a modern standard for interfacing between web servers and Python applications, designed by Andrew Godwin for the Django project as an asynchronous alternative to WSGI.
Little Primer on GIL and Synchronous Python
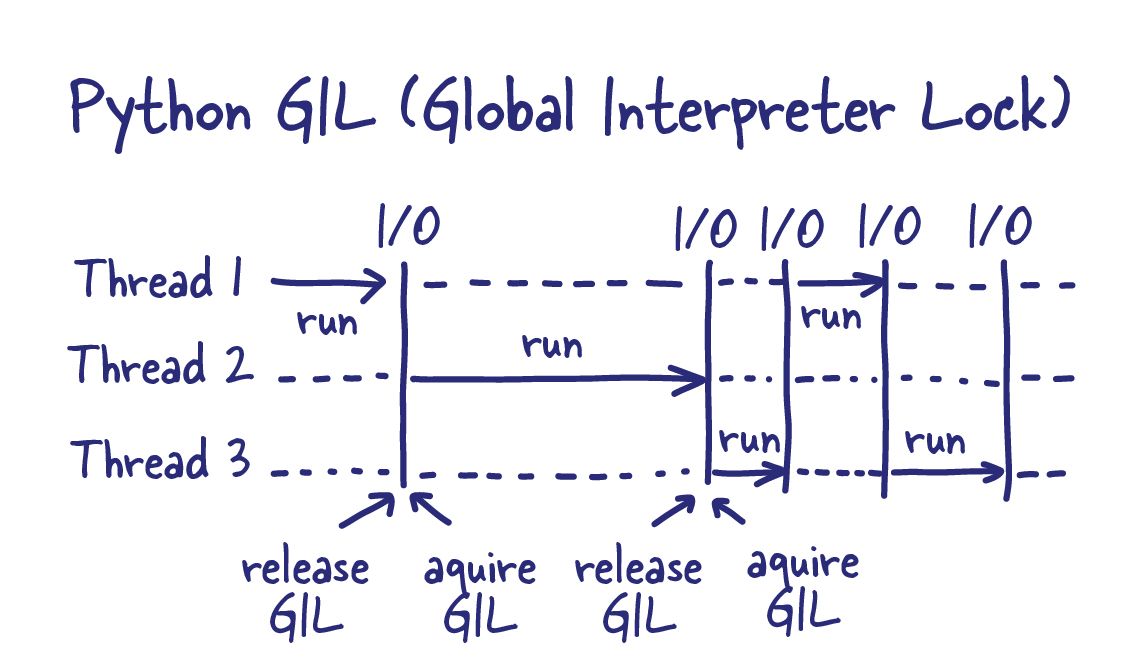
The Python Global Interpreter Lock or GIL, in simple words, is a mutex (or a lock) that allows only one thread to hold the control of the Python interpreter.
Python uses reference counting for memory management, leading to a race condition if multiple threads can change reference counts. No Bueno.
Hence, introducing a global interpreter lock enforces a single execution flow, effectively causing any CPU-bound program to be single-threaded.
Datasette bundles the Uvicorn ASGI server for running on localhost, but it can be hosted by any platform that speaks ASGI: Datasette running on AWS Lambda via Vercel (enabled by the datasette-publish-vercel plugin) exposes the ASGI application directly, skipping the Uvicorn server.
One benefit of building on top of ASGI is that Datasette can integrate with ASGI middleware. Datasette recently grew gzip support using an ASGI middleware class originally written for Starlette.
SQLite
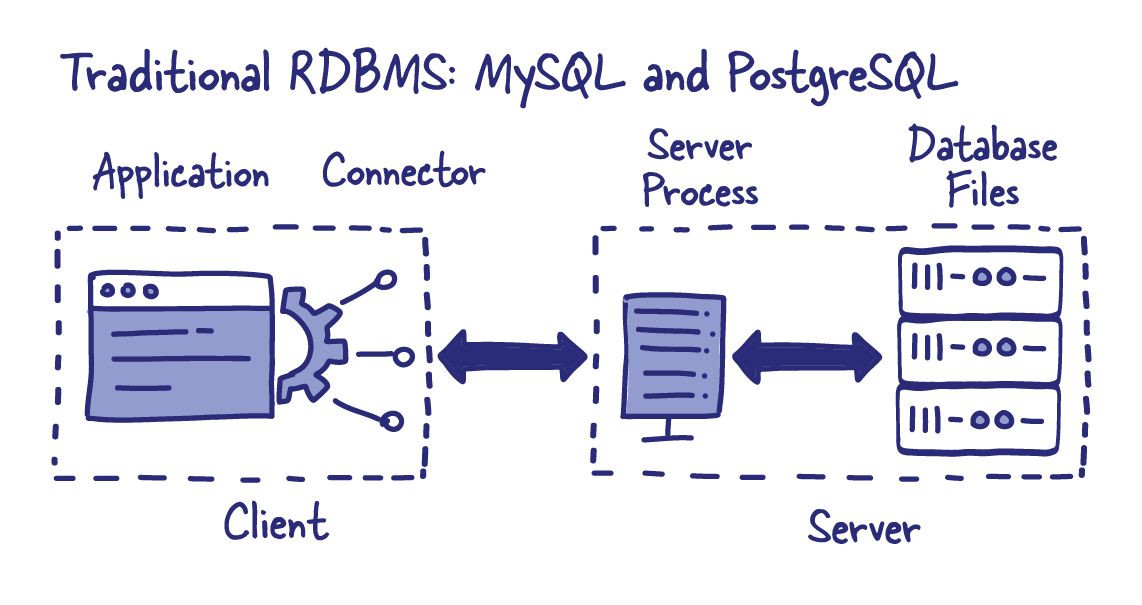
SQLite is key to the design of Datasette. Unlike commonly used databases such as MySQL or PostgreSQL, SQLite doesn’t require running an additional database server: a SQLite database is a file, and the SQLite library can be used to directly access and query the data in that file.
Appropriate Uses For SQLite explains:
SQLite does not compete with client/server databases. SQLite competes with fopen().
SQLite is often underestimated by developers. It provides a modern, extremely fast and extremely well tested relational database engine, and it comes bundled as part of Python in the sqlite3 standard library module. It effortlessly handles many GBs of data and includes powerful features like JSON support and full-text search.
Importantly, a SQLite database is contained in a single binary file. This makes them easy to copy, share and upload to hosting providers. The cognitive overhead involved in working with SQLite databases is tiny: create or download a .db file and you're ready to go.
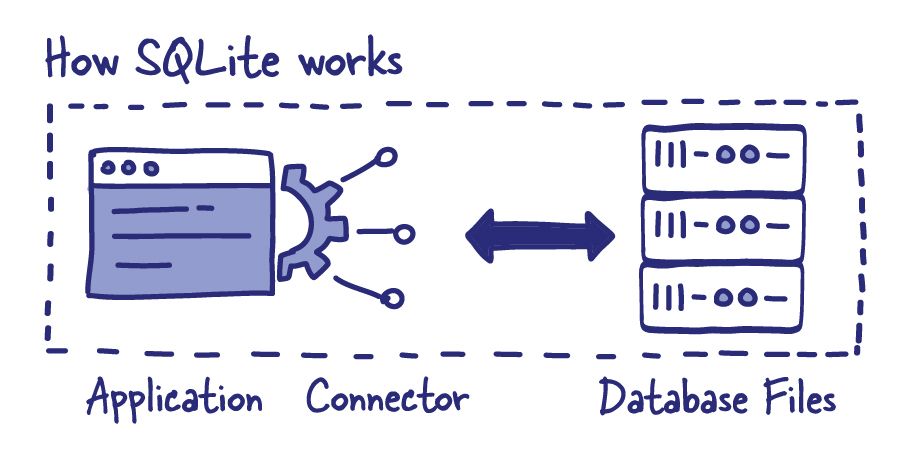
SQLite’s single biggest limitation involves concurrent writes: only one process is allowed to write to a SQLite database at a time.
Since most SQLite writes complete in just a few microseconds this limitation isn't actually much of a problem for real-world applications. Datasette implements an in-Python-memory queue for write operators to ensure they are applied to the database without overlapping each other.
Plugins
Plugins are a crucial piece of the overall Datasette vision. They can extend Datasette’s core functionality with additional features, and there are already more than 80 of them listed in the plugins directory.
Plugins can be used for a wide variety of things:
- Visualization tools, such as datasette-cluster-map for maps or datasette-vega for charts
- Authentication: datasette-auth-passwords adds password protection, while datasette-auth-github and datasette-auth0 provide integration with SSO services
- Additional output formats: datasette-geojson can output data as GeoJSON, datasette-atom provides Atom feeds and datasette-ics can output data as a subscribable calendar feed
- Adding entirely new routes to the application: datasette-graphql adds a
/graphqlendpoint speaking the GraphQL query language
The goal is for there to eventually be hundreds of plugins covering every possible form of visualization or data manipulation that users might need for their projects.
Plugins have a major impact on Datasette’s architecture. Designing plugin hooks forces me to think extremely hard about the design of different aspects of Datasette. I’m increasingly moving core pieces of Datasette’s functionality to use the same hook mechanism as the plugins.
Designing these hooks is really hard! Over time I’ve found that it’s crucial to avoid the temptation to add a hook until you have at least two (and ideally more) potential plugins in mind that can use it. One of the main reasons I haven’t shipped a 1.0 release of Datasette yet is the pressure to make sure the plugin hooks are designed right, since future breaking changes to them would require a major version bump and I’m hoping to provide as much stability as possible.
Plugins also allow me to try out wild ideas without risk of over-complicating Datasette’s core. I started building datasette-graphql as a GraphQL skeptic - I thought SQL was a better querying language, and wanted to prove that I was right. Building the plugin convinced me otherwise - it turns out GraphQL queries excel at retrieving deeply nested structures, which are much harder to achieve using regular SQL. This can result in many N+1 SQL query patterns under the hood, but SQLite is uniquely well suited to handling these because Many Small Queries Are Efficient In SQLite.
Having a risk-free way to try out new ideas is a huge productivity and motivational boost for the overall project.
Supporting Arbitrary SQL queries
Datasette allows end users to execute their own arbitrary SQL queries against the database, for example this one. This is potentially a very dangerous feature - in most web applications this would be classed as SQL injection, a serious class of security vulnerability!
SQL Injection
A SQL injection is a security threat that allows an attacker to manipulate the SQL queries that the application sends to the database. That way, the attacker might access data that they aren’t authorized to see, such as other users’ data. Worse yet is the scenario in which the attacker can get write privileges to the database. They can then update or delete data, causing serious and lasting damages.
In addition to preventing attackers from modifying data, Datasette also needs to protect against malicious long-running queries that could exhaust server resources.
Datasette takes several steps to enable this in a safe way:
- Datasette encourages people to only publish the subset of their data that they want to be available to their users. If you don’t include any private data in your Datasette instance you don’t need to worry about it being selected by a query.
- SQLite database connections are opened using immutable mode (for DBs guaranteed not to change) or read-only mode (for databases that may be updated by other processes). This disallows any write queries that might make it to the connection somehow.
- Datasette rejects any queries that are not SELECT queries, based on an allow-list of regular expressions.
- Queries are executed with a time limit. This cancels any query with an error if it takes longer than a specific limit - one second by default, but this can be customized by the Datasette administrator.
The time limit mechanism uses the sqlite3 set_progress_handler() method. This can be used to run a custom Python function to run after every N instructions executed by the SQLite virtual machine. Datasette’s custom handler checks how long the query has been running and terminates it if it has exceeded the time limit.
Time limits are used in other places too. Datasette displays suggested facets showing columns that could be interesting to facet by, based on checking if that column has a unique value count in a specific range.
These suggestion queries are executed optimistically against each column in the table with a lower time limit of just 50ms. If the query takes longer than that it is canceled and the column is not considered as a suggested facet. This is necessary because the suggested queries are more of a cosmetic enhancement - in a table with 20 columns and 2 million rows calculating these suggestions could take 20 seconds using the default 1s time limit!
Users of the Datasette JSON API can use this optimistic time limit pattern to build their own features, by appending ?_timelimit=5 to the query string (example).
The ability to run arbitrary SQL queries can be disabled by Datasette administrators using the permissions system.
AsyncIO, threading and database connections
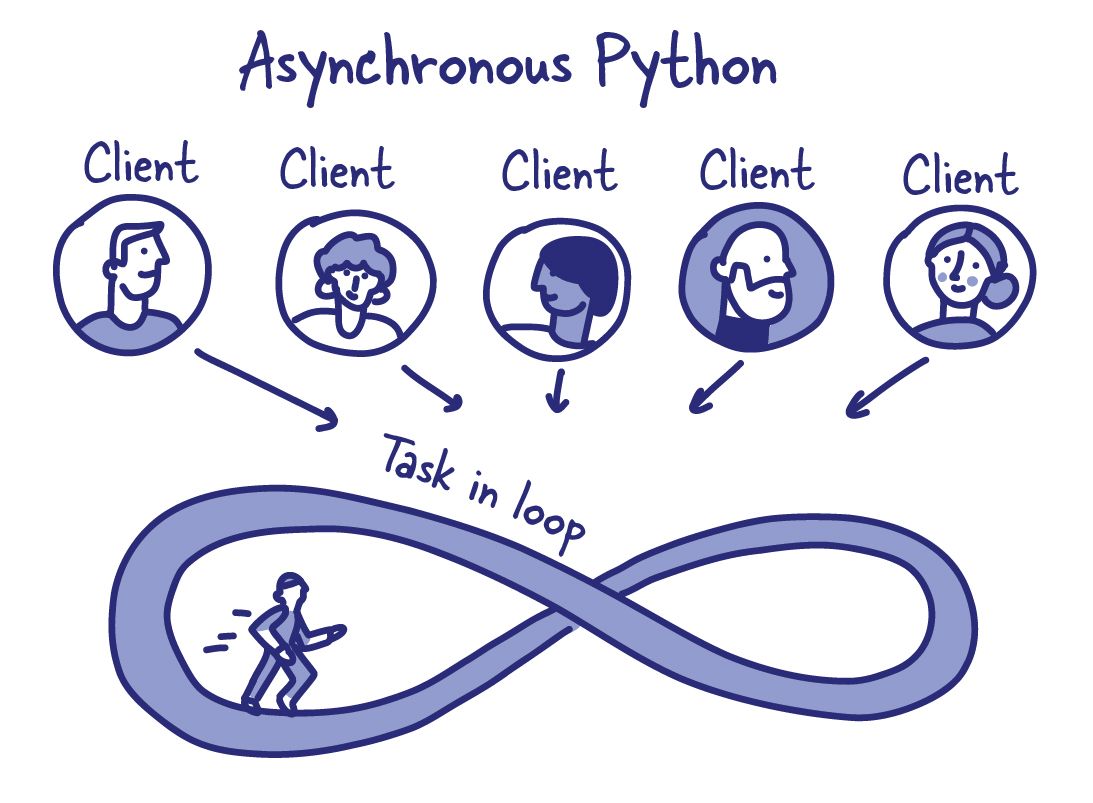
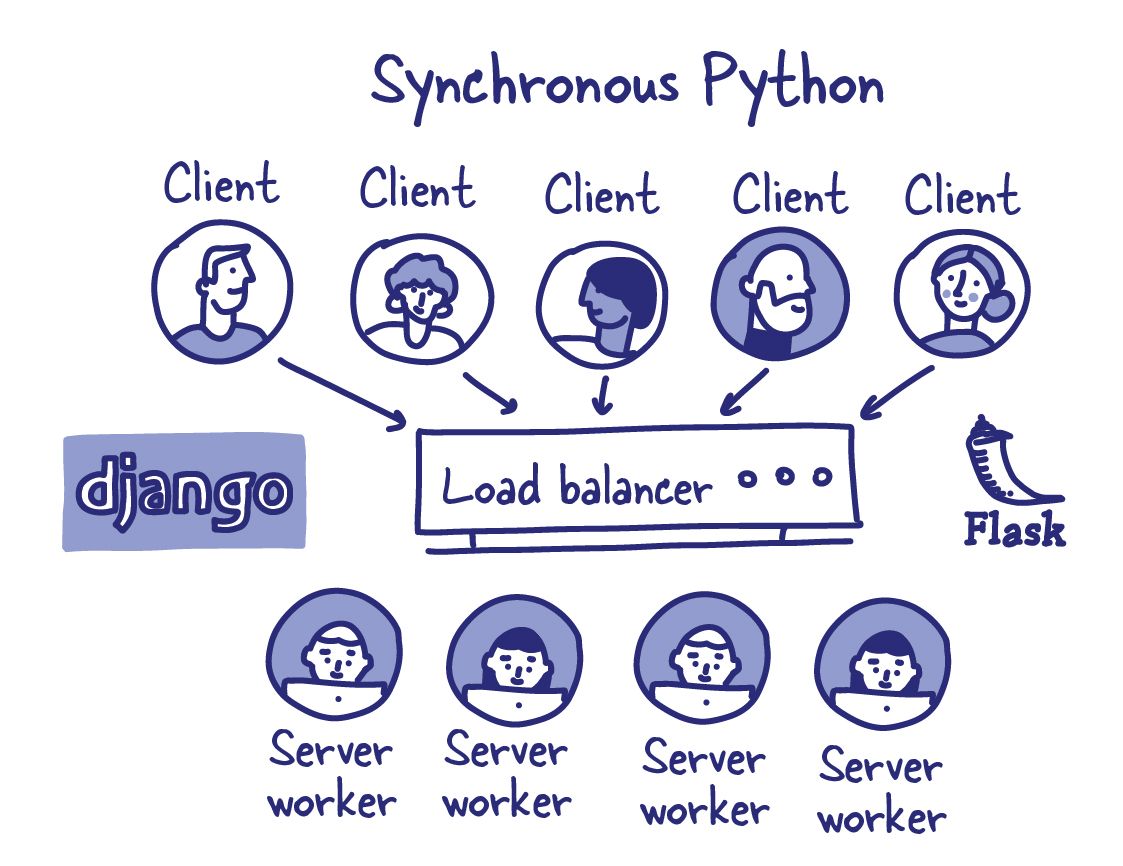
I decided to build Datasette on top of the new asyncio mechanism introduced in Python 3 right from the start, partly as a learning exercise and partly because I hoped that doing so would allow me to handle more parallel connections and give me options for clever integrations with external systems.
With hindsight, it’s not clear to me that those benefits have really proven themselves. I still enjoy the asyncio paradigm but I’m not confident that it has given me any huge wins for this project over writing traditional non-asyncio code.
The biggest problem here is that Python currently lacks a way of performing truly asynchronous queries against a SQLite database.
Since the SQLite querying methods are all blocking, the safe way to query SQLite from an asyncio application is via threads. Libraries such as aiosqlite use threads under the hood.
There isn’t yet a SQLite alternative to asyncpg for PostgreSQL, which provides true asynchronous querying.
Datasette runs SQL read queries in a thread using asyncio.get_event_loop().run_in_executor() where the executor is defined here.
Each of these worker threads has a “connections” thread local, with a connection object for each attached database. This means that if you have 5 attached database files you’ll end up with 15 total connections - 3 read connections for each. I haven’t yet done the research to figure out the optimal configuration here.
Write queries work slightly differently. SQLite requires that only a single connection writes to a database at any one time, so Datasette maintains a dedicated thread wrapping a single write connection for each database that accepts writes.
Writes are then sent to that thread via a queue, using an open source library called Janus which provides a queue that can bridge the gap between the asyncio and threaded Python worlds.
New write operations are added to that queue from the main Datasette asyncio thread. The write thread reads from the queue, executes the writes in turn and places any result back on a reply queue. The calling code can opt to block awaiting that response in asyncio land, or can fire-and-forget the query and move on without waiting for it to complete.
Here’s the code for that. I wrote more about this in Weeknotes: Datasette writes.
Deploying Datasette with “datasette publish” and Baked Data
I want people to publish their data using Datasette. Hosting web applications is still way harder than it should be, so I've invested a lot of effort in making deploying Datasette as easy as possible.
The Datasette CLI tool includes a “publish” command which can be used to deploy Datasette along with a database to a variety of different hosting providers, powered by the publish_subcommand plugin hook.
By default this can be published to Google Cloud Run and Heroku. If you have a database file called legislators.db - and you've previously installed and configured the Heroku or Google Cloud CLI tools - you can deploy it to Cloud Run using the following:
datasette publish cloudrun legislators.db --service=congress-legislatorsOr for Heroku:
datasette publish heroku mydatabase.db -n congress-legislatorsYou can also deploy directly to Vercel or Fly.io if you first install the datasette-publish-vercel or datasette-publish-fly plugins.
All four of these deployment mechanisms use the same trick: they treat the SQLite database file as a binary asset to be applied along with the Datasette application. Fly and Cloud Run both run Docker images, so the scripts build a Docker image that bakes the database in with the code. Vercel and Heroku use slightly different mechanisms - a shim around AWS Lambda functions in the case of Vercel and a buildpack for Heroku - but they both also bundle the database file as part of the deploy.
I call this pattern of bundling up the database along with the rest of the deployment the Baked Data architectural pattern.
Datasette Desktop - Datasette in Electron
I want people to be able to run Datasette on their own laptops. My target users are people who are data literate - they understand rows and columns and maybe work with data professionally - but are not necessarily software engineers themselves.
Telling people to install Python (often after first installing Homebrew) and learn to operate “pip” just so they can use my software is an intolerable level of friction!
Last year I did a research spike to see if I could get Datasette to work as an installable desktop application. I chose Electron for this, since Datasette is already a web application and my hope was that I could wrap it in an Electron shell with as few changes to the core application as possible.
The research spike was a success, and I developed it into a full supported product which I called Datasette Desktop.
When you install and run Datasette Desktop, a native application window opens running the Datasette interface. macOS menu items provide options for opening SQLite databases or opening CSV files, plus a way to search for and install plugins.
There are a lot of moving parts needed to make this happen. The biggest challenge here was to figure out how to include a full Python environment with an installable desktop application.
I couldn’t guarantee that the user would already have Python installed, and I didn’t want to have to walk them through that installation process.
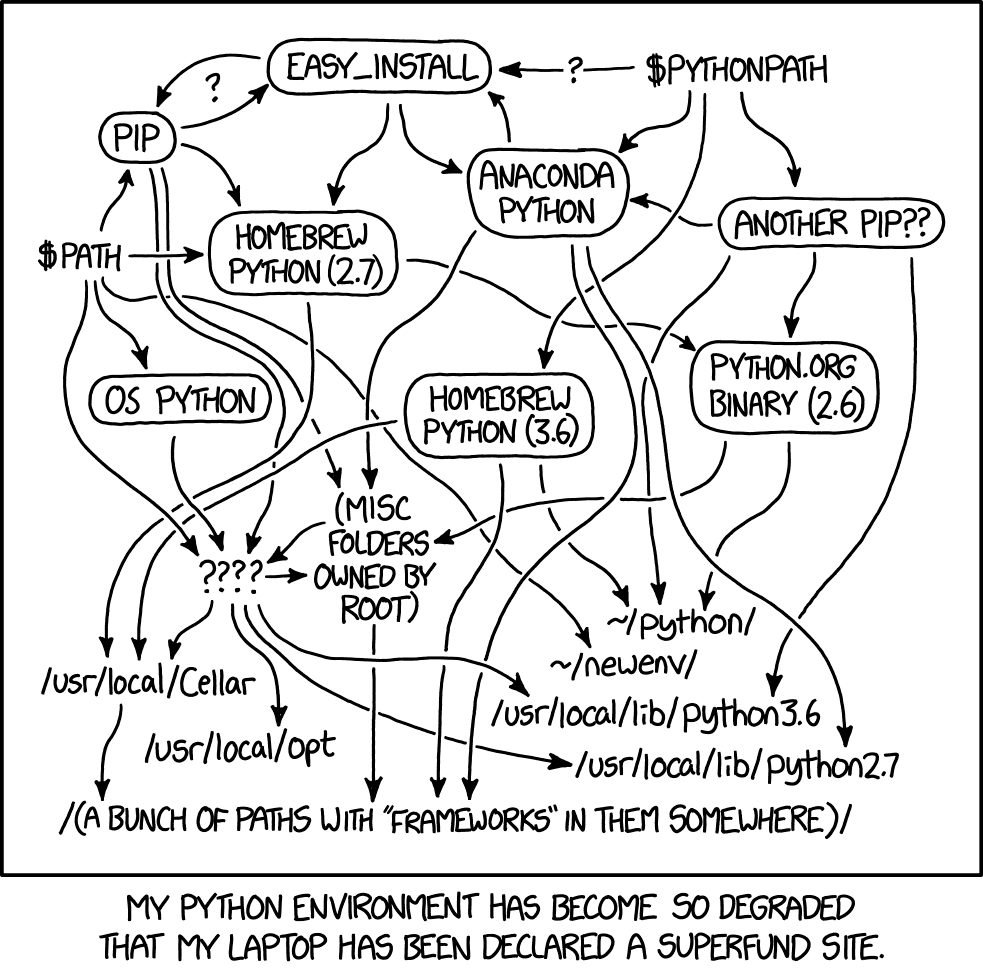
I also needed to be confident that Datasette Desktop would not conflict with any existing Python installations they had and make the XKCD 1987 situation even worse for them!
Then I found python-build-standalone by Gregory Szorc, which produces “self-contained, highly-portable Python distributions”. It turned out to be exactly what I needed.
Datasette Desktop bundles a full standalone copy of Python as part of its macOS application bundle, including the full Python standard library.
When the application first starts, it uses that Python to create a brand new invisible virtual environment in the ~/.datasette-app/venv directory on the user’s machine. It then installs the latest Datasette directly into that environment.
It uses a dedicated virtual environment in order to support the installation of plugins. If the user manages to break the application by installing the wrong plugins they can recover by deleting that folder and restarting the application.
The Electron application itself is 1200 lines of JavaScript which starts the Python Datasette server running, restarts it after a new plugin is installed and configures the various menu options that let the user control how the application behaves.
A custom Datasette plugin called datasette-app-support adds some extra API endpoints to Datasette which the Electron JavaScript wrapper can call to activate specific custom actions - importing a CSV file or creating a new blank database for example.
My top concern in building Datasette Desktop was that I wanted to avoid slowing down the development of Datasette core: I didn’t want changes I made to the main product to require additional considerations for the macOS application.
This final design - with any customizations for the app encapsulated exclusively in a plugin - was effective in achieving that goal.
Datasette Lite - Datasette in the browser
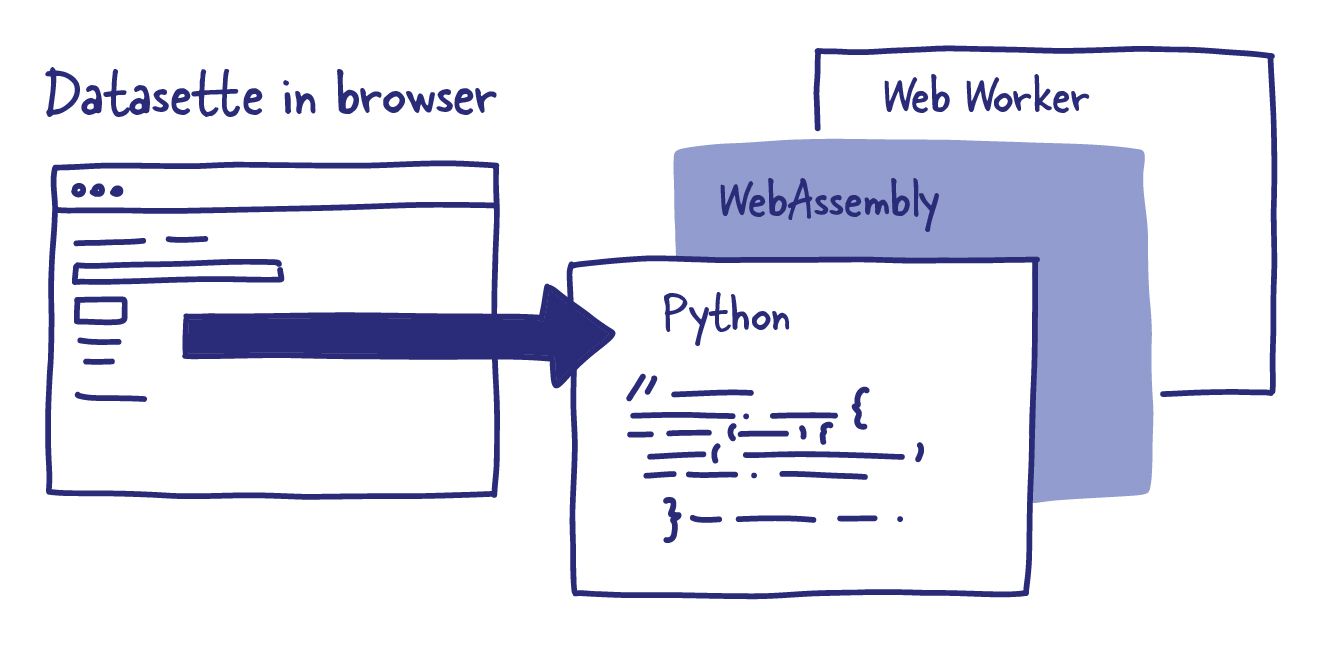
My latest attempt at making Datasette as easy to host as possible was to see if it was possible to run it without any server at all, using Pyodide - an absolutely incredible distribution of Python that compiles it to WebAssembly so that it can run directly in a user’s browser.
I was convinced that Datasette could be run in this way by JupyterLite, an astonishing system that provides the full Jupyter Lab environment - a complex Python web application - running in the browser.
As with Datasette Desktop, this started out as a research spike.
I like to do research like this in a GitHub Issues thread - here’s the thread I used for the prototype. You can follow that for a blow-by-blow account of the different techniques I tried to get this working.
I ended up figuring out that running Datasette in Pyodide in a web worker was the best strategy. Web workers allow JavaScript web applications to run CPU intensive code in a separate process, such that they won’t block the main browser UI thread. Running Python in WebAssembly is exactly the kind of thing they are good for!
datasette.client is an internal API mechanism within Datasette that lets Python code make calls to Datasette’s HTTP endpoints without having to do a round-trip over the network. I originally built it with the idea that plugins could benefit with the same JSON APIs that Datasette exposes to the outside world, and as a utility for running automated tests.
It turned out to be exactly what I needed to build Datasette Lite as well.
Web worker scripts run separately from the visible page, and can’t directly manipulate the DOM. Instead, they communicate with code running on the page via message passing.
Datasette Lite instantiates a Datasette object in the web worker, then uses message passing to receive user navigation events and send back the resulting HTML.
So each time the user clicks a link in the parent window, that URL is sent to the web worker where Datasette generates the full HTML of the page just as if it was running as a regular server-side application.
The web worker sends that HTML (and the status code and content-type) back to the parent window, which injects it into the page using innerHTML.
I’m shocked how well this approach works! The entire implementation is less than 300 lines of JavaScript.
As with Datasette Desktop, my aim here is to be able to run Datasette with as few modifications as possible - such that I don’t lose velocity on the core project due to concerns about how changes might impact Datasette Lite.
How well I’ll be able to keep that is yet to be discovered: I only built Datasette Lite a few weeks ago and it’s mainly still a tech demo, although it already looks like it will grow to be an important part of the overall Datasette ecosystem.
You can reach out to Simon on Twitter here, his personal blog here, Github here and LinkedIn here.
If you want to join the community of just under 5K strong, get a weekly newsletter on software architecture, technology deep dives, and future Arc Notes from the companies you use every day. Subscribe below!
References

 Real PythonReal Python
Real PythonReal Python



 Electron
Electron


[ comments ]